Four Times Speedup By Throttling
In my previous naive experiment I realized 22k small messages per second to my Elixir based small message TCP server. I treat the old post as a baseline and, in my new posts I will experiment with different factors to make this faster.
These posts are not about the Elixir language or its performance. These are about a way to find a good messaging pattern and setup where I can use Elixir in a distributed server environment. Over the years I did this a few times in other languages like Ruby, Lua and C++. I really want to use Elixir on the server side for a number of reasons so I just need to know what is feasible here.
Update: you may be also interested in the next two posts in this series:
- 250k messages per second achieved by better use of Elixir pattern matching
- over 2M messages per second achieved by removing the usage of the Task module
Lock step messaging
The original approach used the conventional Request/Reply pattern. The C++ client sent a small message and it waited for a reply. When the messages are large, this approach is not so bad because the OS overhead and the message roundtrip time is amortized by the data transfer time. In my case when I want to experiment with small messages this doesn’t work very well.
Everytime I send a small message on the loopback network to another process at least these will happen:
- the data gets copied to the kernel space
- a context switch happens from the user to the kernel
- the receiver gets notified by the arrival of the new data
- the data gets copied to the user space
- another context switch to the user program
- the user program processes the data and generates a reply
- … plus steps 1-6 again when sending back the reply
Async acknowledgement with throttling
I have the freedom to relax the protocol, so I will not require to send an immedate acknowledgement to the client. I also change the reply structure to be able to batch the ACKs.
In the original protocol I only sent back the 8 byte ID I received in the request. Now I am going to send this instead:
- ID
- Number of skipped ACKs
I allow the server to send back ACKs whenever it wants, the only thing I require is to tell how many ACKs it has omitted. The ID field is the latest ID that is not skipped.
Using this ACK throttling I let the client decide how much it wants to continue without acknowledgement and decide what to do if the ACKs are not to its taste. If the client detects an error it can close the connection and resend the unacknowledged messages.
On the server side I periodically collect the messages waiting for acknowledgement, pick the latest’s ID and count the other messages. I send this every 5 milliseconds.
Results
elapsed usec=1003507 avg(usec/call)=10.0351 avg(call/msec)=99.6505 avg(call/sec)=99650.5
elapsed usec=1001873 avg(usec/call)=10.0187 avg(call/msec)=99.8131 avg(call/sec)=99813.1
elapsed usec=1002957 avg(usec/call)=10.0296 avg(call/msec)=99.7052 avg(call/sec)=99705.2
elapsed usec=1013812 avg(usec/call)=10.1381 avg(call/msec)=98.6376 avg(call/sec)=98637.6
elapsed usec=1022114 avg(usec/call)=10.2211 avg(call/msec)=97.8364 avg(call/sec)=97836.4
elapsed usec=1292082 avg(usec/call)=12.9208 avg(call/msec)=77.3945 avg(call/sec)=77394.5
elapsed usec=968613 avg(usec/call)=9.68613 avg(call/msec)=103.24 avg(call/sec)=103240
elapsed usec=971822 avg(usec/call)=9.71822 avg(call/msec)=102.9 avg(call/sec)=102900
elapsed usec=979073 avg(usec/call)=9.79073 avg(call/msec)=102.137 avg(call/sec)=102137
elapsed usec=1003730 avg(usec/call)=10.0373 avg(call/msec)=99.6284 avg(call/sec)=99628.4
elapsed usec=989953 avg(usec/call)=9.89953 avg(call/msec)=101.015 avg(call/sec)=101015
elapsed usec=1070109 avg(usec/call)=10.7011 avg(call/msec)=93.4484 avg(call/sec)=93448.4
elapsed usec=1020841 avg(usec/call)=10.2084 avg(call/msec)=97.9584 avg(call/sec)=97958.4
elapsed usec=994713 avg(usec/call)=9.94713 avg(call/msec)=100.532 avg(call/sec)=100532
elapsed usec=1000015 avg(usec/call)=10.0001 avg(call/msec)=99.9985 avg(call/sec)=99998.5
elapsed usec=1009947 avg(usec/call)=10.0995 avg(call/msec)=99.0151 avg(call/sec)=99015.1
elapsed usec=997890 avg(usec/call)=9.9789 avg(call/msec)=100.211 avg(call/sec)=100211
elapsed usec=1055865 avg(usec/call)=10.5587 avg(call/msec)=94.7091 avg(call/sec)=94709.1
elapsed usec=991912 avg(usec/call)=9.91912 avg(call/msec)=100.815 avg(call/sec)=100815
elapsed usec=1023854 avg(usec/call)=10.2385 avg(call/msec)=97.6702 avg(call/sec)=97670.2
It is roughly 4x more than it was previously. I saved a lot on the OS overhead and a bit on the processing part too.
Does this scale to multiple cores?
Unfortunately, no. Check the figures below. The aggregate performance slightly increases with a second parallel client and starts dropping at the thrird client.
My purpose is not to measure the maximum Elixir performance, neither to squeeze as much from my PC as possible. I want to understand what practices lead to a feasible solution if I want to my server code to use Elixir.
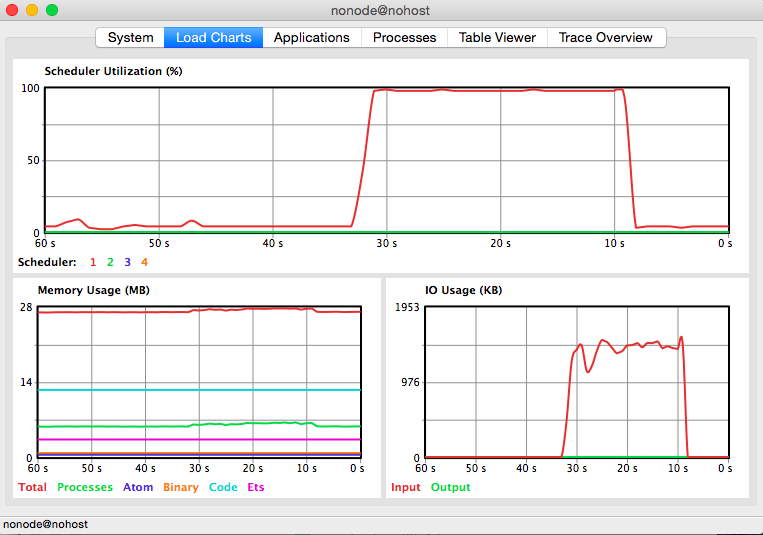
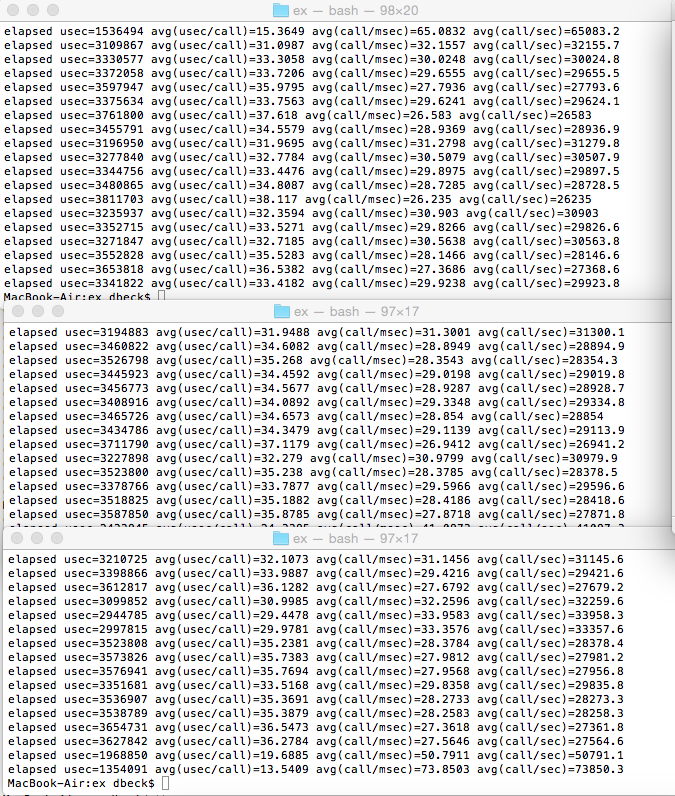
Single client stats
Here is the output of :observer.start:
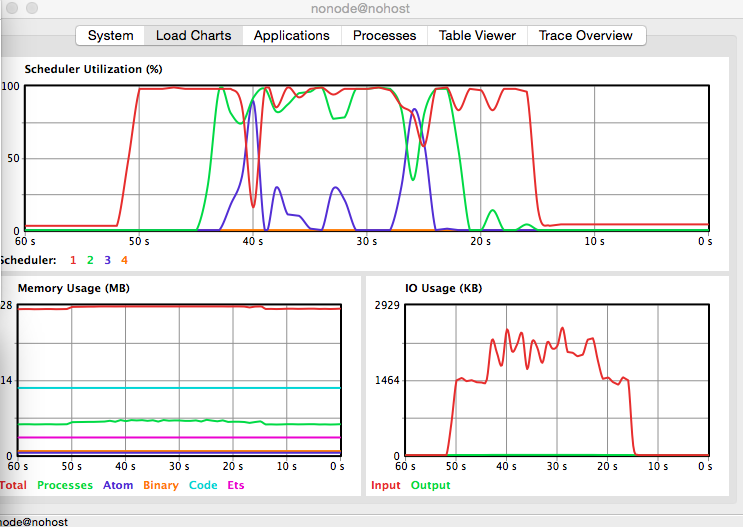
Double client stats
When I start two clients at the same time the aggregate performance slightly increases to about 120k messages per second. Here is the output of :observer.start:
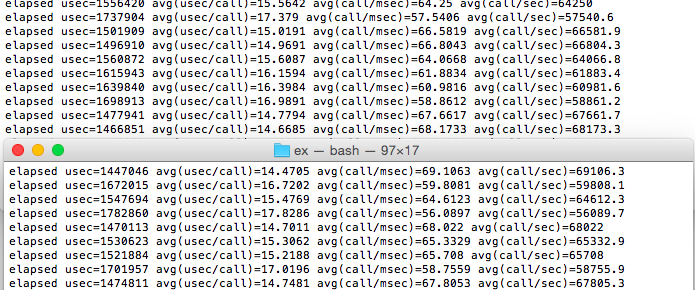
And the statistics:
Triple client stats
Starting 3 clients in parallel causes contention somewhere because the aggregate performance starts dropping below 100k msg/sec. My gut feeling is that my codes are too badly written and they cause too much pressure on the OS. Here is the output of :observer.start:
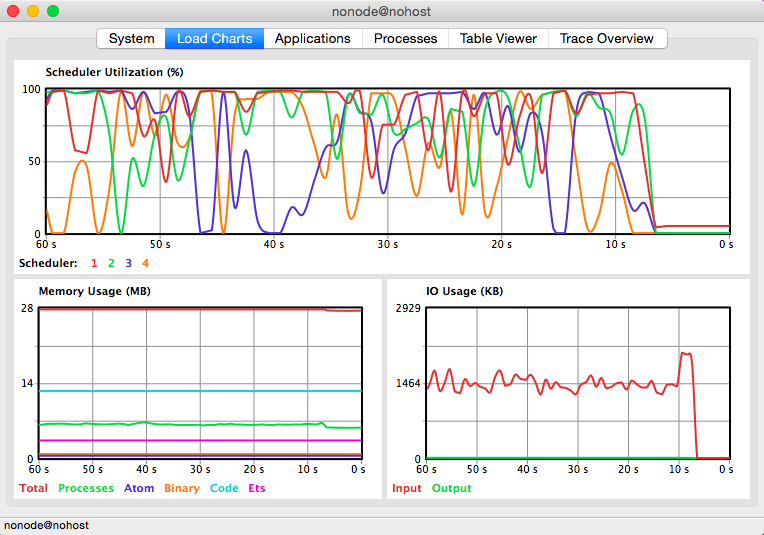
And the statistics:
Who is slow?
100k small messages per second is not bad on the loopback network but compared to the 10 million persistent local messages in my local queue experiment is not so good. I have a few ideas where to improve this, but let’s leave them for other posts. I only collect facts here:
- If I don’t send any ACKs back to the client and neither do any processing on the Elixir side the numbers are roughly the same. Around 110k messages per second. Again, without sending back data to the client.
- When I am sending back the periodic ACKs, the Elixir server takes a whole CPU core (100%) and the C++ client takes around 15% of another core.
- Both the Elixir server and the C++ client calls the OS for every single message in my code. In fact the Elixir server reads every message in two parts, the {ID, Size} first and the Data second. This puts too much and unnecessary pressure on the OS.
- The C++ side should also batch the writes at least to reach the IP packet size, so the IP and TCP packet wrapping, checksum, context switch, OS costs … would be amortized over multiple messages.
The code
The code is roughly the same as in the previous experiment. I only changed the module name in these files:
- mix.exs
- lib/throttle_perf.ex
- lib/throttle_worker.ex
ThrottlePerf.Container
I added a ThrottlePerf.Container module in lib/throttle_perf_container.ex:
defmodule ThrottlePerf.Container do
def start_link do
Agent.start_link(fn -> [] end)
end
def stop(container) do
Agent.stop(container)
end
def flush(container) do
Agent.get_and_update(container, fn list -> {list, []} end)
end
def push(container, id, data) do
Agent.update(container, fn list -> [{id, data}| list] end)
end
defp generate([]) do
{}
end
defp generate( [{id, _}] ) do
{id, 0}
end
defp generate( [{id, _} | tail] ) do
tail_len = List.foldl(tail, 0, fn (_, acc) -> 1 + acc end)
{id, tail_len}
end
def generate_ack(list) do
generate(list)
end
end
I am still an Elixir beginner, so forgive my bad practices. The push function stores the incoming message ID and Data into a list and flush function replaces the container with an empty one and returns the accumulated data. The generat_ack function is a helper to transform the flushed list to an ACK message.
ThrottlePerf.Handler
The Handler module in lib/throttle_perf_handler.ex is responsible for the conversation:
defmodule ThrottlePerf.Handler do
def start_link(ref, socket, transport, opts) do
pid = spawn_link(__MODULE__, :init, [ref, socket, transport, opts])
{:ok, pid}
end
def init(ref, socket, transport, _Opts = []) do
:ok = :ranch.accept_ack(ref)
{:ok, container} = ThrottlePerf.Container.start_link
timer_pid = spawn_link(__MODULE__, :timer, [socket, transport, container])
loop(socket, transport, container, timer_pid)
end
def flush(socket, transport, container) do
list = ThrottlePerf.Container.flush(container)
case ThrottlePerf.Container.generate_ack(list) do
{id, skipped} ->
packet = << id :: binary-size(8), skipped :: little-size(32) >>
transport.send(socket, packet)
{} ->
IO.puts "empty data, everything flushed already"
end
end
def timer(socket, transport, container) do
flush(socket, transport, container)
receive do
{:stop} ->
IO.puts "stop command arrived"
:stop
after
5 ->
timer(socket, transport, container)
end
end
def shutdown(socket, transport, container, timer_pid) do
ThrottlePerf.Container.stop(container)
:ok = transport.close(socket)
send timer_pid, {:stop}
end
def loop(socket, transport, container, timer_pid) do
case transport.recv(socket, 12, 5000) do
{:ok, id_sz_bin} ->
<< id :: binary-size(8), sz :: little-size(32) >> = id_sz_bin
case transport.recv(socket, sz, 5000) do
{:ok, data} ->
ThrottlePerf.Container.push(container, id, data)
loop(socket, transport, container, timer_pid)
{:error, :timeout} ->
flush(socket, transport, container)
shutdown(socket, transport, container, timer_pid)
_ ->
shutdown(socket, transport, container, timer_pid)
end
_ ->
shutdown(socket, transport, container, timer_pid)
end
end
end
I start a linked timer process that waits for being stopped, otherwise it collects the messages waiting for acknowledgement and sends an ACK, every 5 milliseconds. The flush function does the actual message sending. The loop function is the one who controls the flow.
The C++ client
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/uio.h>
#include <sys/select.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <string.h>
#include <unistd.h>
#include <stdio.h>
#include <iostream>
#include <functional>
#include <cstdint>
#include <chrono>
#include <thread>
namespace
{
//
// to help freeing C resources
//
struct on_destruct
{
std::function<void()> fun_;
on_destruct(std::function<void()> fun) : fun_(fun) {}
~on_destruct() { fun_(); }
};
//
// for measuring ellapsed time and print statistics
//
struct timer
{
typedef std::chrono::high_resolution_clock highres_clock;
typedef std::chrono::time_point<highres_clock> timepoint;
timepoint start_;
uint64_t iteration_;
timer(uint64_t iter) : start_{highres_clock::now()}, iteration_{iter} {}
int64_t spent_usec()
{
using namespace std::chrono;
timepoint now{highres_clock::now()};
return duration_cast<microseconds>(now-start_).count();
}
~timer()
{
using namespace std::chrono;
timepoint now{highres_clock::now()};
uint64_t usec_diff = duration_cast<microseconds>(now-start_).count();
double call_per_ms = iteration_*1000.0 / ((double)usec_diff);
double call_per_sec = iteration_*1000000.0 / ((double)usec_diff);
double us_per_call = (double)usec_diff / (double)iteration_;
std::cout << "elapsed usec=" << usec_diff
<< " avg(usec/call)=" << us_per_call
<< " avg(call/msec)=" << call_per_ms
<< " avg(call/sec)=" << call_per_sec
<< std::endl;
}
};
}
int main(int argc, char ** argv)
{
try
{
// create a TCP socket
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if( sockfd < 0 )
{
throw "can't create socket";
}
on_destruct close_sockfd( [sockfd](){ close(sockfd); } );
// server address (127.0.0.1:8000)
struct sockaddr_in server_addr;
::memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
server_addr.sin_port = htons(8000);
// connect to server
if( connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1 )
{
throw "failed to connect to server at 127.0.0.1:8000";
}
// prepare data
char data[] = "Hello";
uint64_t id = 0;
uint32_t len = 5;
int64_t last_ack = -1;
struct iovec data_iov[3] = {
{ (char *)&id, 8 }, // id
{ (char *)&len, 4 }, // len
{ data, 5 } // data
};
//
// this lambda function checks if we have received a new ACK.
// if we did then it checks the content and returns the max
// acknowledged ID. this supports receiving multiple ACKs in
// a single transfer.
//
auto check_ack = [sockfd](int64_t last_ack) {
int64_t ret_ack = last_ack;
fd_set fdset;
FD_ZERO(&fdset);
FD_SET(sockfd, &fdset);
// give 1 ms to the acks to arrive
struct timeval tv { 0, 1000 };
int select_ret = select( sockfd+1, &fdset, NULL, NULL, &tv );
if( select_ret < 0)
{
throw "failed to select, socket error?";
}
if( select_ret > 0 && FD_ISSET(sockfd,&fdset) )
{
// max 2048 acks that we handle in one check
size_t alloc_bytes = 12 * 2048;
std::unique_ptr<uint8_t[]> ack_data{new uint8_t[alloc_bytes]};
//
// let's receive what has arrived. if there are more than 2048
// ACKs waiting, then the next loop will take care of them
//
auto recv_ret = recv(sockfd, ack_data.get(), alloc_bytes, 0);
if( recv_ret < 0 )
{
throw "failed to recv, socket error?";
}
if( recv_ret > 0 )
{
for( size_t pos=0; pos<recv_ret; pos+=12 )
{
uint64_t id = 0;
uint32_t skipped = 0;
// copy the data to the variables above
memcpy(&id, ack_data.get()+pos, sizeof(id) );
memcpy(&skipped, ack_data.get()+pos+sizeof(id), sizeof(skipped) );
// check the ACKs
if( (ret_ack + skipped + 1) != id )
{
throw "missing ack";
}
ret_ack = id;
}
}
}
return ret_ack;
};
for( int i=0; i<20; ++i )
{
size_t iter = 100000;
timer t(iter);
int64_t checked_at_usec = 0;
// send data in a loop
for( size_t kk=0; kk<iter; ++kk )
{
if( writev(sockfd, data_iov, 3) != 17 )
{
throw "failed to send data";
}
//
// check time after every 1000 send so I reduce
// OS calls by not querying time too often
//
if( (kk%1000) == 0 )
{
//
// check if at least 30 msecs has ellapsed since the
// last ACK check
//
int64_t spent_usec = t.spent_usec();
if( spent_usec > (checked_at_usec+30000) )
{
last_ack = check_ack(last_ack);
checked_at_usec = spent_usec;
}
}
++id;
}
// wait for all outstanding ACKs
while( last_ack < (id-1) )
last_ack = check_ack(last_ack);
}
while( last_ack < (id-1) )
{
last_ack = check_ack(last_ack);
if( last_ack != id )
{
std::cerr << "last_ack=" << last_ack << " id=" << id << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
}
catch( const char * msg )
{
perror(msg);
}
return 0;
}
Conclusion
The tradeoff is the additional complexity in error handling and code in exchange for 4x speed improvement. I still need to rationalize both the client and server side to do larger reads and writes in order to put less pressure on the OS.