Scalesmall W1 Combininig Events
This is the second episode of the scalesmall experiment. In the previous post I touched a few areas I want to experiment with. Since then I made a few design decisions and also progressed with the implementation.
During this first week I was focusing on the shared state and the high level structure of the group_manager application. It’s purpose is to manage the node states and coordinate their participation in the groups’s goal. The :group_manager app runs on each node and supervises one or more groups through the GroupManager.Master supervisor.

Status
I made few steps around designing the OTP supervision tree and I have made sure it does start, but not much apart from that yet. When I start two groups: apple and orange then the supervision tree looks like this:
Erlang/OTP 18 [erts-7.1] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false] [dtrace]
Interactive Elixir (1.1.1) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)> GroupManager.join
join/2
iex(1)> GroupManager.join("a@127.0.0.1", "apple")
{:ok, #PID<0.146.0>}
iex(2)> GroupManager.join("a@127.0.0.1", "orange")
{:ok, #PID<0.151.0>}
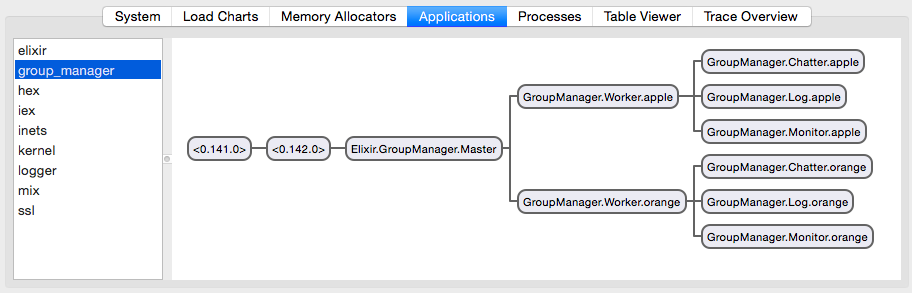
The idea is that a single Master supervisor has GroupManager.Worker children. Each worker is named after the group it serves, and they have three children:
- GroupManager.Chatter is responsible for communication, sending and receiving messages from other group members.
- GroupManager.Log holds the group state in a Log like structure that should be in sync with other members of the group.
- GroupManager.Monitor detects other members being dead or alive and generates an event when a group member disappears.
Apart from the Master is being able to start and stop Worker instances together with their children, not much is implemented on this front. I wanted to start with designing the model of what the nodes think about the shared state of the group together with the messages.
The purpose of the group
A crucial thing that I owe you since the beginning. In scalesmall, the group is a management unit of nodes that coordinates group membership, work distribution and location. There are no leader or follower roles in the group, all nodes participate with equal rights.
The location in the group is represented by a double precision floating point number ranging between 0.0 and 1.0. This has the same purpose as the hash key in consistent hashing schemes. Nodes are responsible for serving one or more subranges in the key range.
The responsibility of handling a subrange is represented in a list. Each node that serves the given subrange is on this list. The head of the list has the highest priority for the subrange and each subsequent nodes have less priority.
So the group:
- is a collection of member nodes with equal rights
- is a way to manage resources by serving subranges of 0..1
- is a way to locate resources within subranges
Events in the group
High level events in the group are:
- a node joins or leaves the group
- a node is getting full and wants to stop serving a subrange
- a node joins the group and picks up a subrange
- a node detects that its resources are over/under utilized and wants to change its priority for a subrange
To support these high level events I want to pass these low level events between group members:
- Join(Node)
- Leave(Node)
- Split(At)
- Register(At, Node)
- Release(At, Node)
- Promote(At, Node)
- Demote(At, Node)
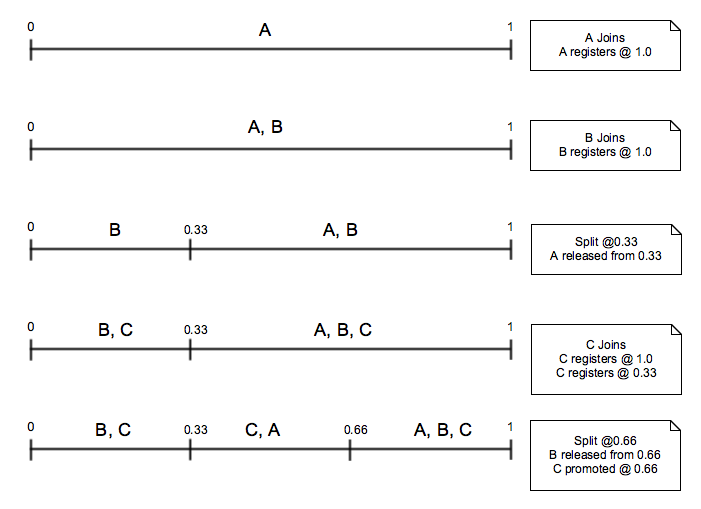
A high level illustration of what happens with the ranges and their nodes for different events:
Shared group state
I want the group to have the same view about which nodes are available and what subranges are served by whom. To reach this agreement I want to cut a few corners. First is that the group may see independent events that the nodes can combine. For example, when a node receives a join request from NodeX and another node receives a join request from NodeY, then these two events can be safely combined without the need of coordination. Not even the order of the events count.
Similarly to the Join/Leave events I can merge Range events (Split/Register/Release/Promote/Demote) for the majority of cases with the help of a few simple rules. When a node sees two conflicting Range events it should use a majority decision to accept one of them.
I imagine the shared group state being a log of events similarly to the blockchain ledger. This ledger should be based on a Merkle tree, where each entry holds:
- a hash variable of the previous entry
- event data
- a hash of the current entry
Going through the log of events each node must be able to calculate the same view of the shared state. When events are combined the resulting events hash will change too, so the communication vehicle must make sure that the sender nodes will see the combined event too.
Here are the rules and explanations of each event types:
Join and Leave events
Join events are generated when a node wants to join the group. The event is first sent by the (gateway) node where the joining node first connects to. Leave events are generated by any node in the group who detects the given node is down.
Join/Leave event merging rules are:
- two Join(/Leave) events for the same node can be combined and treated as a single event
- two Join(/Leave) events for different nodes can be combined to a sorted list of events (sorted by the node name)
- Join and Leave events for the same node cannot be combined, they are in conflict (for simplicity reasons)
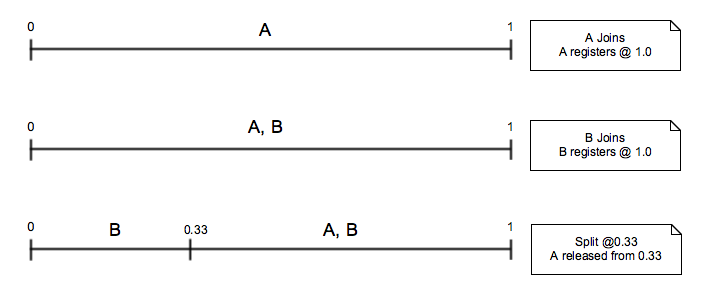
Split event
Split events are sent by the group participants in preparation for handing off part of a subrange. When a node decides that the data (load/resource) it handles is approaching its capacity it first decides if it wants to handoff an entire subrange or only a part of the subrange. For the latter case the node sends a Split event together with a Release event.
The Split event alone doesn’t change the resource distribution between the nodes, only there will be one additional subrange.

All impacted nodes will be automatically assigned to the new subrange. If the node wants to stop serving the subrange it must also send the Release event.
Split event rules are:
- two Split events for the same split point going to be merged
- two Split events for different split points will be sorted and concatenated
- Split events cannot conflict. they may impact other Range events as described below
I assume there will be a smart algorithm that decides which parts or what subranges will be handed off by the nodes. Future tense, because I only have a few ideas about that, nothing is fixed so far.
Register and Release events
Register and Release events are sent by the node who wants to be responsible or hand off a subrange. When it first joins the group no subranges are assigned automatically to the node. When it wants to be responsible for a subrange, first it needs to get the data for the subrange so it can serve it. When the data is in sync then it sends a Register event so it can serve the subrange too. When a node wants to stop serving a subrange it needs to send a Release event so it gets removed from the subrange.
Rules for Register and Release events are:
- two Register(/Release) events for the same (Node, Point) pair will be merged into one
- Register and Release events for the same (Node, Point) pair are in conflict
- two Register(/Release) events for different (Node, Point) pairs will be concatenated and sorted by Point and then Node
- Split events that impacts the subrange of a Register(/Release) event will split the Register(/Release) event too
Just like Split I don’t have the algorithm for deciding what subranges the new node should participate in.
Promote and Demote events
Promote and Demote events are sent by the node who wants to change their priority in serving the given subrange. That will be determined by the yet-to-invent-super-smart algorithm. When a node registers for a subrange it will be appended to the list of serving nodes for the subrange, thus receiving the lowest priority. If the super-smart algorithm decides that the node gets bored by being at the end of the list it can ask for promotion by sending the Promote message. When the messages goes through, it will cause the node and the one above in rank to be swapped.
Demote events do the opposite of Promote. One way to decide ranks could be based on utilization. So when a node gets more utilized, it could go for demotion as a preparation of later Split plus Release. Again, this is yet to be figured out.
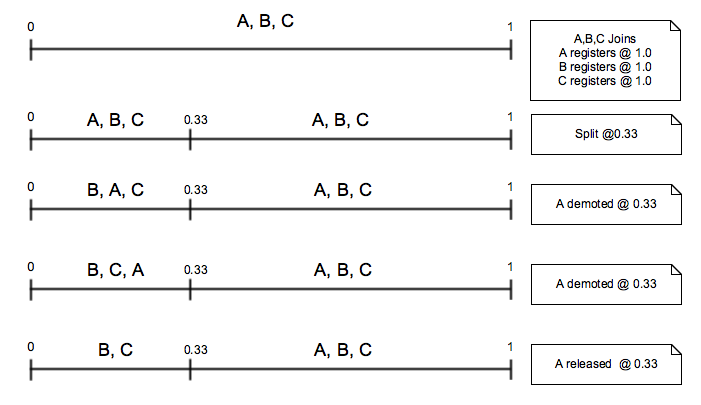
Rules for Promote and Demote events are:
- two Promote(/Demote) events for the same (Node, Point) pair will be merged into one
- Promote and Demote events for the same (Node, Point) pair are in conflict
- two Promote(/Demote) events for different (Node, Point) pairs will be concatenated and sorted by Point and then Node
- Split events that impacts the subrange of a Promote(/Demote) event will split the Promote(/Demote) event too
Putting this together
The two classes of events are the RangeEvent and the StatusEvent.
The group’s shared state is composed of log entries. These log entries have a set of status and range events with the following structure:
LogEntry has:
- hash of the previous entry
- sorted list of status events 1)
- sorted list of range events, which in turn has: 2)
- sorted list of split events
- sorted list of release events
- sorted list of register events
- sorted list of promote events
- sorted list of demote events
- hash of the current entry
From the above 1) and 2) are implemented during the first week of the experiment as GroupManager.StatusEvent.Event and GroupManager.RangeEvent.Event.
The individual Range events are in GroupManager.RangeEvent.Split and GroupManager.RangeEvent.Node.
A set of tests had been written for the merge and split logic under the range_event and the status_event test folders.
Why floating point ranges and not SHA1/MD5 hashes
I can ask the same, why hashes? Consistent hashing first became popular when Napster, Gnutella, Bittorrent and other P2P file sharing networks started spreading.
For the file sharing use-case I see the use of consistent hashing over a large value range because of the large number of participants and files. In riak for example, where a limited number of vnodes are serving the 2^160 range, I don’t fully understand why to use such a big range.
May be when this experiment progresses further, I will know more about that. With the floating point numbers, I see the advantage of being able to split ranges easily (within acceptable limits) and native support for arithmetic operations. Another advantage is the smaller value size, 8 bytes versus 20 for SHA1.
Plan for the next week
I would like to progress with the Log structure of the shared state.
Episodes
- Ideas to experiment with
- More ideas and a first protocol that is not in use anymore
- Got rid of the original protocol and looking into CRDTs
- My first ramblings about function guards
- The group membership messages
- Design of a mixed broadcast
- My ARM based testbed
- Experience with defstruct, defrecord and ETS
- GroupManager code works, beta
- GroupManager more information and improvements