Passing Millions Of Small Tcp Messages In Elixir
The last post of my TCP experiment series shows how easy it is to achieve a huge performance gain in Elixir if you are lucky (like me) or you know your Elixir trade (others). In my previous experiments I had to build on my existing experience with network programming in C++ which didn’t bring too much results. I could speed up my original design design from 22k messages per second to 100k messages per second and finally to 250k messages per second.
One might say, by cheating. I just dropped the Request/Reply pattern for an asynch communication pattern. Thus comparing apples to oranges. So the overall 11x improvement from 22k to 250k is just 2x if I was playing fair.
Comparing messaging patterns
The Request/Reply pattern did this:

The Throttled Reply pattern is doing this:
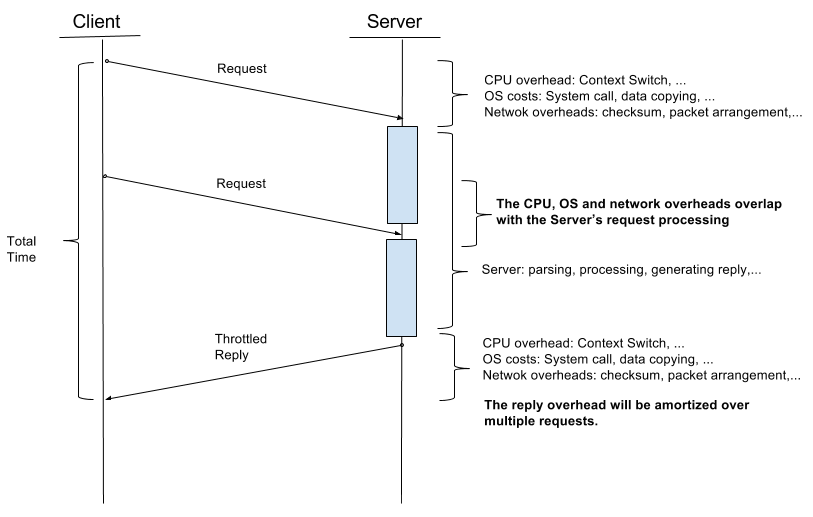
What has changed
In this last experiment I have not changed too many things. I just identified a performance hog in my Elixir code: the Task module. I used it for collecting messages and to generate the throttled reply periodically with the help of another timer process, using the data I collected in the Collection module. My assumption was that I will gain performance by putting the reply generation to an async process and save processing time in the handler. It turned out that it is faster to generate the reply in the handler process than passing the work to the async Task.
This is quite contrary to my previous understanding, that using Erlang processes for async tasks is the best way to arrange things.
I think what best describes my results is pure luck. I knew the performance of my previous experiment was not good enough, but I didn’t have anything else in my toolbox than random rambling in the code and hope I can do it better. I know that, this is because of my little Elixir knowledge and I guess someone with enough experience would have been able to pinpoint the problem in my previous attempts.
Results
With my latest changes I start to see over 2M messages per second which starts to be in the same ballpark of my simple local persistent queues 10M messages.
elapsed usec=475458 avg(usec/call)=0.475458 avg(call/msec)=2103.2352 avg(call/sec)=2103235.2
elapsed usec=503925 avg(usec/call)=0.503925 avg(call/msec)=1984.4223 avg(call/sec)=1984422.3
elapsed usec=440032 avg(usec/call)=0.440032 avg(call/msec)=2272.562 avg(call/sec)=2272562
elapsed usec=418468 avg(usec/call)=0.418468 avg(call/msec)=2389.669 avg(call/sec)=2389669
elapsed usec=416838 avg(usec/call)=0.416838 avg(call/msec)=2399.0135 avg(call/sec)=2399013.5
elapsed usec=422835 avg(usec/call)=0.422835 avg(call/msec)=2364.9887 avg(call/sec)=2364988.7
elapsed usec=413266 avg(usec/call)=0.413266 avg(call/msec)=2419.749 avg(call/sec)=2419749
elapsed usec=408301 avg(usec/call)=0.408301 avg(call/msec)=2449.1735 avg(call/sec)=2449173.5
elapsed usec=402846 avg(usec/call)=0.402846 avg(call/msec)=2482.3382 avg(call/sec)=2482338.2
elapsed usec=406217 avg(usec/call)=0.406217 avg(call/msec)=2461.7384 avg(call/sec)=2461738.4
elapsed usec=401122 avg(usec/call)=0.401122 avg(call/msec)=2493.0071 avg(call/sec)=2493007.1
elapsed usec=402261 avg(usec/call)=0.402261 avg(call/msec)=2485.9482 avg(call/sec)=2485948.2
elapsed usec=427914 avg(usec/call)=0.427914 avg(call/msec)=2336.9182 avg(call/sec)=2336918.2
elapsed usec=404582 avg(usec/call)=0.404582 avg(call/msec)=2471.6868 avg(call/sec)=2471686.8
elapsed usec=411407 avg(usec/call)=0.411407 avg(call/msec)=2430.683 avg(call/sec)=2430683
elapsed usec=404555 avg(usec/call)=0.404555 avg(call/msec)=2471.8518 avg(call/sec)=2471851.8
elapsed usec=413125 avg(usec/call)=0.413125 avg(call/msec)=2420.5749 avg(call/sec)=2420574.9
elapsed usec=398185 avg(usec/call)=0.398185 avg(call/msec)=2511.3955 avg(call/sec)=2511395.5
elapsed usec=406304 avg(usec/call)=0.406304 avg(call/msec)=2461.2113 avg(call/sec)=2461211.3
The elixir code change
I renamed the project to Sync and replaced all Batch references. The big change is the removal of lib/batch_container.ex and the reply generation logic went into the slightly more complicated process functions. I no longer need the timer process, so that is also gone.
The previous lib/batch_handler.ex module had:
defmodule Batch.Handler do
def start_link(ref, socket, transport, opts) do
pid = spawn_link(__MODULE__, :init, [ref, socket, transport, opts])
{:ok, pid}
end
def init(ref, socket, transport, _Opts = []) do
:ok = :ranch.accept_ack(ref)
{:ok, container} = Batch.Container.start_link
timer_pid = spawn_link(__MODULE__, :timer, [socket, transport, container])
transport.setopts(socket, [nodelay: :true])
loop(socket, transport, container, timer_pid, << >>)
end
def flush(socket, transport, container) do
list = Batch.Container.flush(container)
case Batch.Container.generate_ack(list) do
{id, skipped} ->
packet = << id :: binary-size(8), skipped :: little-size(32) >>
transport.send(socket, packet)
{} ->
:ok
end
end
def timer(socket, transport, container) do
flush(socket, transport, container)
receive do
{:stop} -> :stop
after
5 -> timer(socket, transport, container)
end
end
def loop(socket, transport, container, timer_pid, yet_to_parse) do
case transport.recv(socket, 0, 5000) do
{:ok, packet} ->
not_yet_parsed = process(container, yet_to_parse <> packet)
loop(socket, transport, container, timer_pid, not_yet_parsed)
{:error, :timeout} ->
flush(socket, transport, container)
shutdown(socket, transport, container, timer_pid)
_ ->
shutdown(socket, transport, container, timer_pid)
end
end
defp process(_container, << >> ) do
<< >>
end
defp process(container, packet) do
case packet do
<< id :: binary-size(8), sz :: little-size(32) , data :: binary-size(sz) >> ->
Batch.Container.push(container, id, data)
<< >>
<< id :: binary-size(8), sz :: little-size(32) , data :: binary-size(sz) , rest :: binary >> ->
Batch.Container.push(container, id, data)
process(container, rest)
unparsed ->
unparsed
end
end
defp shutdown(socket, transport, container, timer_pid) do
Batch.Container.stop(container)
:ok = transport.close(socket)
send timer_pid, {:stop}
end
end
The new lib/sync_handler.ex module has:
defmodule Sync.Handler do
def start_link(ref, socket, transport, opts) do
pid = spawn_link(__MODULE__, :init, [ref, socket, transport, opts])
{:ok, pid}
end
def init(ref, socket, transport, _Opts = []) do
:ok = :ranch.accept_ack(ref)
transport.setopts(socket, [nodelay: :true])
loop(socket, transport, << >>)
end
def loop(socket, transport, yet_to_parse) do
case transport.recv(socket, 0, 5000) do
{:ok, packet} ->
case process(yet_to_parse <> packet, << >>, 0) do
{not_yet_parsed, {id, skipped} } ->
packet = << id :: binary-size(8), skipped :: little-size(32) >>
transport.send(socket, packet)
loop(socket, transport, not_yet_parsed)
{not_yet_parsed, {} } ->
loop(socket, transport, not_yet_parsed)
end
{:error, :timeout} ->
shutdown(socket, transport)
_ ->
shutdown(socket, transport)
end
end
defp shutdown(socket, transport) do
:ok = transport.close(socket)
end
defp process(<< >>, << >>, _skipped ) do
{ << >>, {} }
end
defp process(<< >>, last_id, skipped ) do
{ << >>, { last_id, skipped } }
end
defp process(packet, << >>, 0) do
case packet do
<< id :: binary-size(8), sz :: little-size(32) , _data :: binary-size(sz) >> ->
{ << >>, { id, 0 } }
<< id :: binary-size(8), sz :: little-size(32) , _data :: binary-size(sz) , rest :: binary >> ->
process(rest, id, 0)
unparsed ->
{ unparsed, {} }
end
end
defp process(packet, last_id, skipped) do
case packet do
<< id :: binary-size(8), sz :: little-size(32) , _data :: binary-size(sz) >> ->
{ << >>, { id, skipped+1 } }
<< id :: binary-size(8), sz :: little-size(32) , _data :: binary-size(sz) , rest :: binary >> ->
process(rest, id, skipped+1)
unparsed ->
{ unparsed, {last_id, skipped} }
end
end
end
Other notes
It is very interesting to see that once I arrived the million messages per second range than small changes that didn’t have an impact before, now started to make huge differences.
For example the setsockopt(TCP_NODELAY) option in the C++ code hurts performance. If I turn it on then the performance drops to 1.5 million messages on my computer. This didn’t have an impact in my previous experiments.
The other factor is the MAX_ITEMS parameter of the buffer<MAX_ITEMS> which seem to be best around 50 and changing it to significantly lower or higher will hurt the performance too.
The C++ client code
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/uio.h>
#include <sys/select.h>
#include <netinet/in.h>
#include <netinet/tcp.h>
#include <arpa/inet.h>
#include <string.h>
#include <unistd.h>
#include <stdio.h>
#include <iostream>
#include <iomanip>
#include <functional>
#include <cstdint>
#include <chrono>
#include <thread>
namespace
{
//
// to help freeing C resources
//
struct on_destruct
{
std::function<void()> fun_;
on_destruct(std::function<void()> fun) : fun_(fun) {}
~on_destruct() { if( fun_ ) fun_(); }
};
//
// for measuring ellapsed time and print statistics
//
struct timer
{
typedef std::chrono::high_resolution_clock highres_clock;
typedef std::chrono::time_point<highres_clock> timepoint;
timepoint start_;
uint64_t iteration_;
timer(uint64_t iter) : start_{highres_clock::now()}, iteration_{iter} {}
int64_t spent_usec()
{
using namespace std::chrono;
timepoint now{highres_clock::now()};
return duration_cast<microseconds>(now-start_).count();
}
~timer()
{
using namespace std::chrono;
timepoint now{highres_clock::now()};
uint64_t usec_diff = duration_cast<microseconds>(now-start_).count();
double call_per_ms = iteration_*1000.0 / ((double)usec_diff);
double call_per_sec = iteration_*1000000.0 / ((double)usec_diff);
double us_per_call = (double)usec_diff / (double)iteration_;
std::cout << "elapsed usec=" << usec_diff
<< " avg(usec/call)=" << std::setprecision(8) << us_per_call
<< " avg(call/msec)=" << std::setprecision(8) << call_per_ms
<< " avg(call/sec)=" << std::setprecision(8) << call_per_sec
<< std::endl;
}
};
template <size_t MAX_ITEMS>
struct buffer
{
// each packet has 3 parts:
// - 64 bit ID
// - 32 bit size
// - data
struct iovec items_[MAX_ITEMS*3];
uint64_t ids_[MAX_ITEMS];
size_t n_items_;
uint32_t len_;
char data_[5];
buffer() : n_items_{0}, len_{5}
{
memcpy(data_, "hello", 5);
for( size_t i=0; i<MAX_ITEMS; ++i )
{
// I am cheating with the packet content to be fixed
// to "hello", but for the purpose of this test app
// it is OK.
//
ids_[i] = 0;
// the ID
items_[i*3].iov_base = (char*)(ids_+i);
items_[i*3].iov_len = sizeof(*ids_);
// the size
items_[(i*3)+1].iov_base = (char*)(&len_);
items_[(i*3)+1].iov_len = sizeof(len_);
// the data
items_[(i*3)+2].iov_base = data_;
items_[(i*3)+2].iov_len = len_;
}
}
void push(uint64_t id)
{
ids_[n_items_++] = id;
}
bool needs_flush() const
{
return (n_items_ >= MAX_ITEMS);
}
void flush(int sockfd)
{
if( !n_items_ ) return;
if( writev(sockfd, items_, (n_items_*3)) != (17*n_items_) )
{
throw "failed to send data";
}
n_items_ = 0;
}
};
}
int main(int argc, char ** argv)
{
try
{
// create a TCP socket
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if( sockfd < 0 )
{
throw "can't create socket";
}
on_destruct close_sockfd( [sockfd](){ close(sockfd); } );
// server address (127.0.0.1:8000)
struct sockaddr_in server_addr;
::memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK);
server_addr.sin_port = htons(8000);
// connect to server
if( connect(sockfd, (struct sockaddr *)&server_addr, sizeof(struct sockaddr)) == -1 )
{
throw "failed to connect to server at 127.0.0.1:8000";
}
{
/* This hurts performance
int flag = 1;
if( setsockopt( sockfd, IPPROTO_TCP, TCP_NODELAY, (void *)&flag, sizeof(flag)) == -1 )
{
throw "failed to set TCP_NODELAY on the socket";
}
*/
}
// the buffer template parameter tells how many messages shall
// we batch together
buffer<50> data;
uint64_t id = 0;
int64_t last_ack = -1;
//
// this lambda function checks if we have received a new ACK.
// if we did then it checks the content and returns the max
// acknowledged ID. this supports receiving multiple ACKs in
// a single transfer.
//
auto check_ack = [sockfd](int64_t last_ack) {
int64_t ret_ack = last_ack;
fd_set fdset;
FD_ZERO(&fdset);
FD_SET(sockfd, &fdset);
// give 1 msec to the acks to arrive
struct timeval tv { 0, 1000 };
int select_ret = select( sockfd+1, &fdset, NULL, NULL, &tv );
if( select_ret < 0)
{
throw "failed to select, socket error?";
}
else if( select_ret > 0 && FD_ISSET(sockfd,&fdset) )
{
// max 2048 acks that we handle in one check
size_t alloc_bytes = 12 * 2048;
std::unique_ptr<uint8_t[]> ack_data{new uint8_t[alloc_bytes]};
//
// let's receive what has arrived. if there are more than 2048
// ACKs waiting, then the next loop will take care of them
//
auto recv_ret = recv(sockfd, ack_data.get(), alloc_bytes, 0);
if( recv_ret < 0 )
{
throw "failed to recv, socket error?";
}
if( recv_ret > 0 )
{
for( size_t pos=0; pos<recv_ret; pos+=12 )
{
uint64_t id = 0;
uint32_t skipped = 0;
// copy the data to the variables above
//
memcpy(&id, ack_data.get()+pos, sizeof(id) );
memcpy(&skipped, ack_data.get()+pos+sizeof(id), sizeof(skipped) );
// check the ACKs
if( (ret_ack + skipped + 1) != id )
{
throw "missing ack";
}
ret_ack = id;
}
}
}
return ret_ack;
};
for( int i=0; i<50; ++i )
{
size_t iter = 1000000;
timer t(iter);
int64_t checked_at_usec = 0;
// send data in a loop
for( size_t kk=0; kk<iter; ++kk )
{
data.push(id);
if( data.needs_flush() )
{
data.flush(sockfd);
}
//
// check time after every 1000 send so I reduce
// OS calls by not querying time too often
//
if( (kk%1000) == 0 )
{
//
// check if at least 30 msecs has ellapsed since the
// last ACK check
//
int64_t spent_usec = t.spent_usec();
if( spent_usec > (checked_at_usec+30000) )
{
last_ack = check_ack(last_ack);
checked_at_usec = spent_usec;
}
}
++id;
}
// flush all unflushed items
data.flush(sockfd);
// wait for all outstanding ACKs
while( last_ack < (id-1) )
last_ack = check_ack(last_ack);
}
while( last_ack < (id-1) )
{
last_ack = check_ack(last_ack);
if( last_ack != id )
{
std::cerr << "last_ack=" << last_ack << " id=" << id << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(1000));
}
}
}
catch( const char * msg )
{
perror(msg);
}
return 0;
}
Finally
I am now satisfied with these results and will work on putting this into production ready code. I plan to create a last wrap-up post to summarize the various lessons I learned during these experiments. The final code will also go to github so interested folks can play with it more easily.